
Dr Qi’s Invited Talks on textattack
On June 24th, 2021, I gave an invited talk at the Science Academy Machine Learning Summer School on “TextAttack: Generalizing Adversarial Examples to Natural...

Deep learning-based natural language processing (deep NLP) plays a crucial role in many security-critical domains, advancing information understanding and analysis for healthcare, legal justice, e-commerce, social media platforms, and many more. Consequently, it is essential to understand the robustness of deep NLP systems to adaptive adversaries. We introduce techniques to automatically evaluate and improve the adversarial robustness of deep NLP frameworks. This topic is a new and exciting area requiring expertise and close collaboration across multiple disciplines, including adversarial machine learning, natural language processing, and software testing.
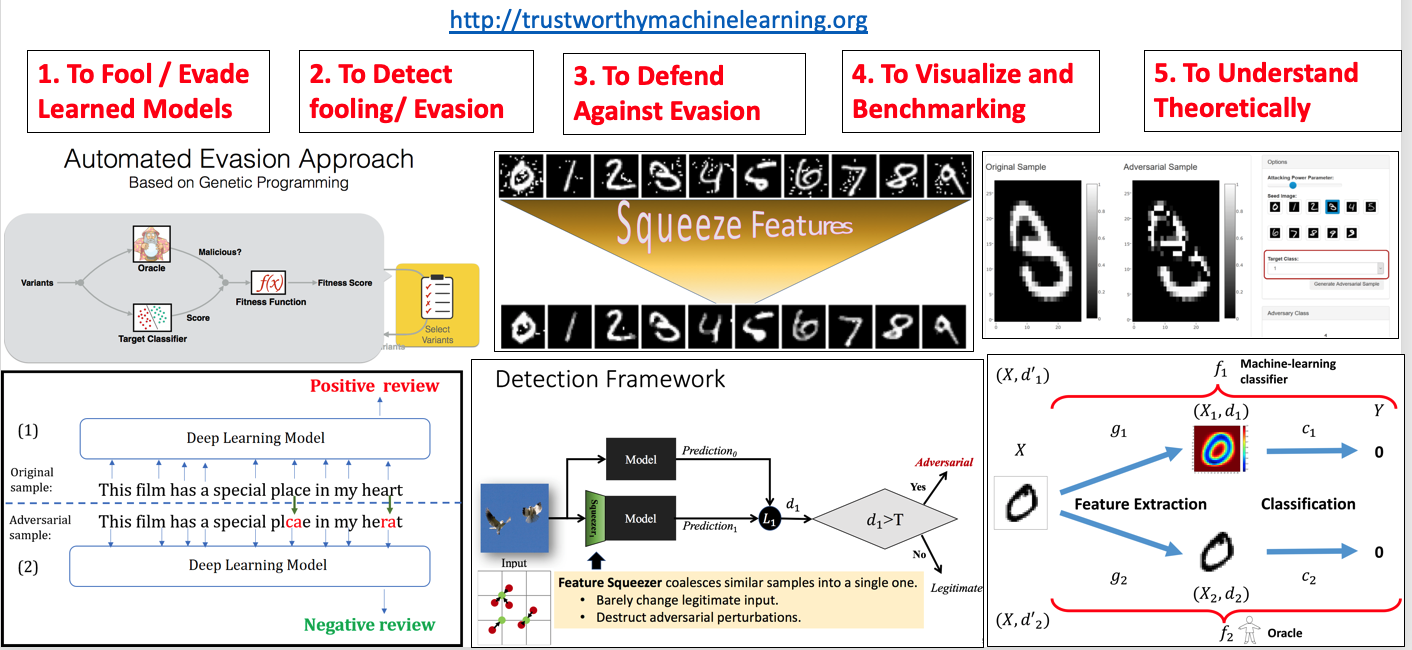
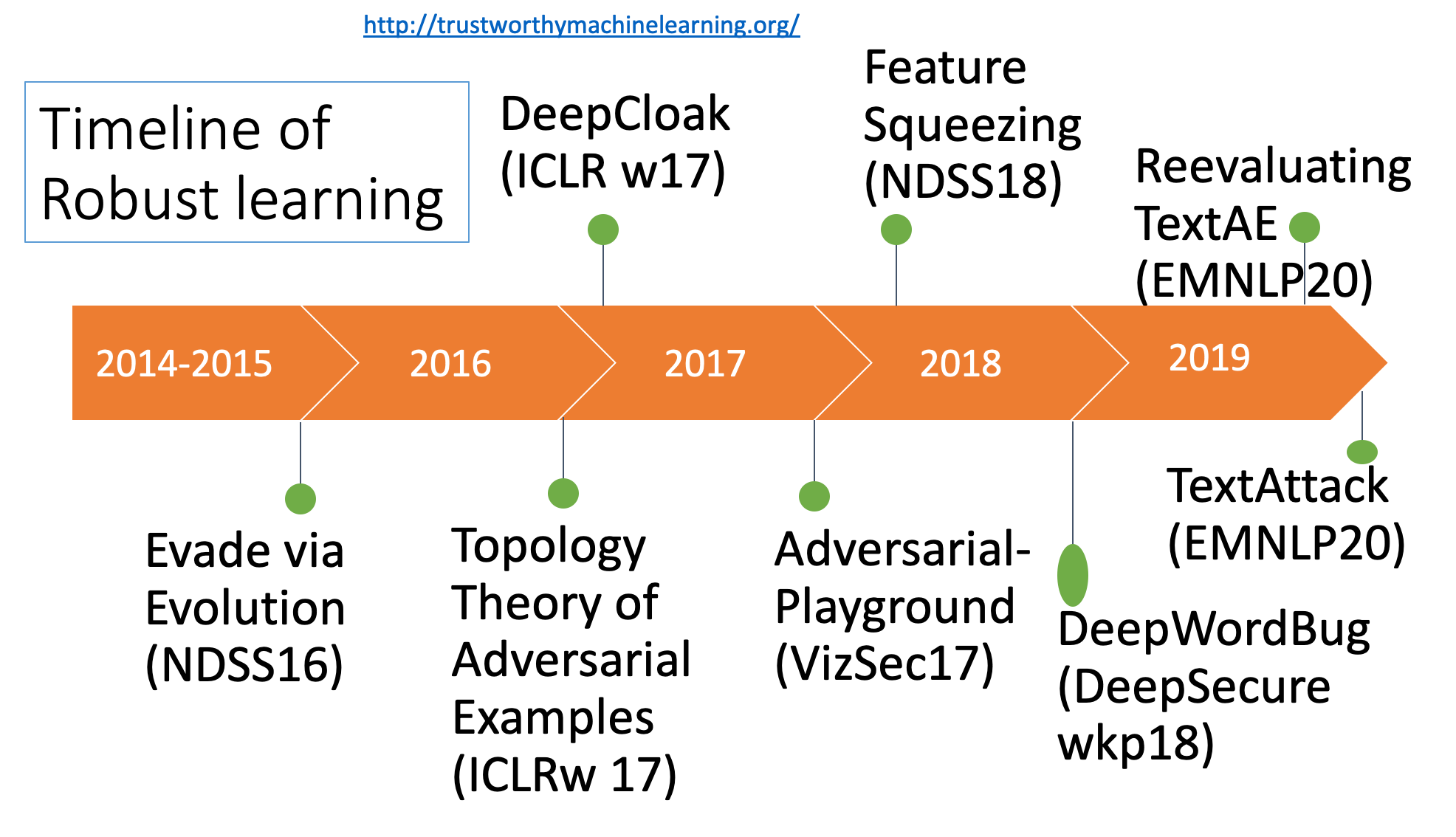
At the junction between NLP, deep learning and computer security, we build toolboxes for five main task as shown in the following table. Our system aims to allow a NLP designer to understand how their NLP system performance degrades under evasion attacks, enabling better-informed and more secure design choices. The framework is general and scalable, and takes advantage of the latest advances in deep NLP and computer security.
| No. | Tool Category | ~~~~~~~ |
Venues | Software |
|---|---|---|---|---|
| 1 | Evade NLP Machine Learning | [TextAttack: A Framework for Adversarial Attacks in Natural Language Processing] | EMNLP2020 | GitHub |
| 2 | Evade Machine Learning | [Automatically Evading Classifiers, Case Study on PDF Malware Classifiers] | NDSS16 | GitHub |
| 3 | Evade NLP Machine Learning | [Black-box Generation of Adversarial Text Sequences to Fool Deep Learning Classifiers] | DeepSecureWkp18 | GitHub |
| 4 | Detect Adversarial Attacks | [Feature Squeezing- Detecting Adversarial Examples in Deep Neural Networks] | NDSS18 | GitHub |
| 5 | Defense against Adversarial Attacks | [DeepCloak- Masking Deep Neural Network Models for Robustness against Adversarial Samples] | ICLRwkp17 | GitHub |
| 6 | Visualize Adversarial Attacks | [Adversarial-Playground- A Visualization Suite for Adversarial Samples] | VizSec17 | GitHub |
| 7 | Theorems of Adversarial Examples | [A Theoretical Framework for Robustness of (Deep) Classifiers Against Adversarial Samples] | ICLRw17 | |
| 8 | Trustworthy via Interpretation | [Deep Motif Dashboard] | ICLRw2017 |
Have questions or suggestions? Feel free to ask me on Twitter or email me.
Thanks for reading!
On June 24th, 2021, I gave an invited talk at the Science Academy Machine Learning Summer School on “TextAttack: Generalizing Adversarial Examples to Natural...
Title: Searching for a Search Method: Benchmarking Search Algorithms for Generating NLP Adversarial Examples
Title: Reevaluating Adversarial Examples in Natural Language
Ph.D. Dissertation Defense by Weilin Xu
On April 23 2019, I gave an invited talk at the ARO Invitational Workshop on Foundations of Autonomous Adaptive Cyber Systems
On December 21 @ 12noon, I gave a distinguished webinar talk in the Fall 2018 webinar series of the Institute for Information Infrastructure Protection (I3P)...
We are releasing EvadeML-Zoo: A Benchmarking and Visualization Tool for Adversarial Examples (with 8 pretrained deep models+ 9 state-of-art attacks).
Jack’s DeepMotif paper (Deep Motif Dashboard: Visualizing and Understanding Genomic Sequences Using Deep Neural Networks ) have received the “best paper awar...
Tool Deep Motif Dashboard: Visualizing and Understanding Genomic Sequences Using Deep Neural Networks
Paper Arxiv