We move the blogs on this research front to our Group-Blog-Site at https://qdata.github.io/qdata-page/ since 2021.
Scope of problems our tools aim to tackle
Classifiers based on machine learning algorithms have shown promising results for many security tasks including malware classification and network intrusion detection, but classic machine learning algorithms are not designed to operate in the presence of adversaries. Intelligent and adaptive adversaries may actively manipulate the information they present in attempts to evade a trained classifier, leading to a competition between the designers of learning systems and attackers who wish to evade them. This project is developing automated techniques for predicting how well classifiers will resist the evasions of adversaries, along with general methods to automatically harden machine-learning classifiers against adversarial evasion attacks.
Important tasks
At the junction between machine learning and computer security, this project involves toolboxes for five main task as shown in the following table. Our system aims to allow a classifier designer to understand how the classification performance of a model degrades under evasion attacks, enabling better-informed and more secure design choices. The framework is general and scalable, and takes advantage of the latest advances in machine learning and computer security.
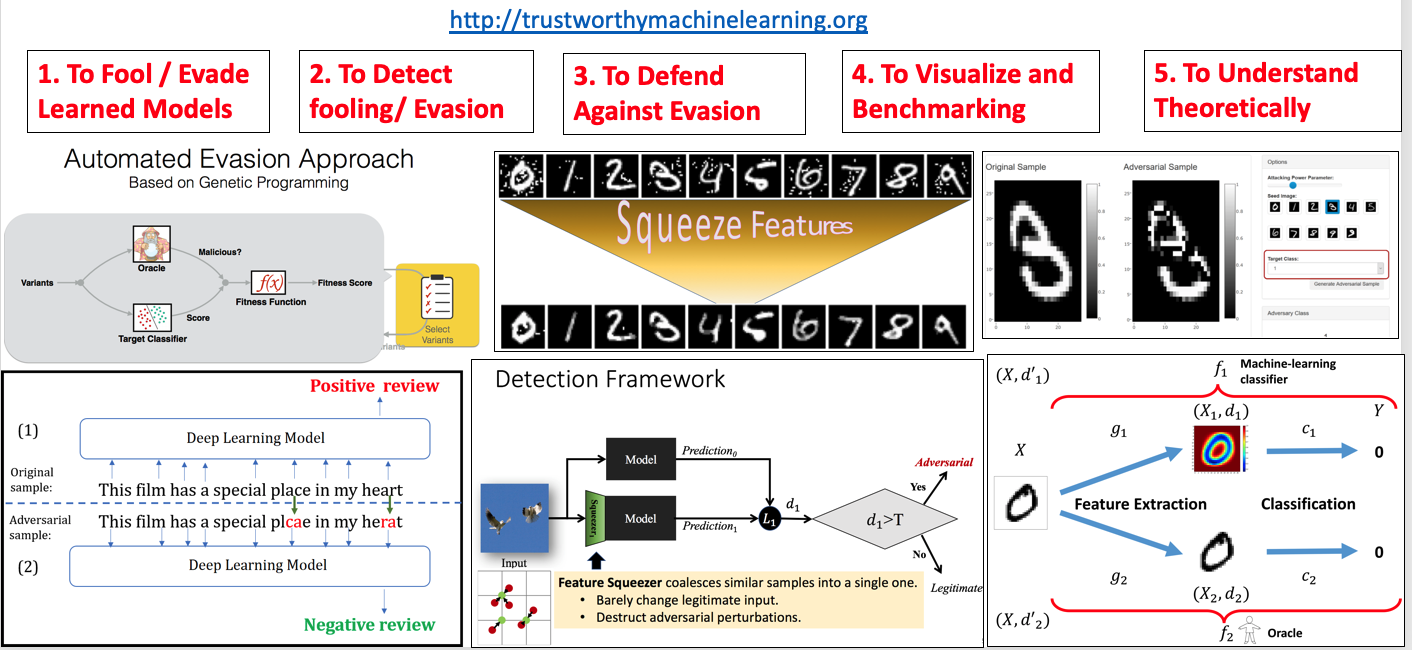
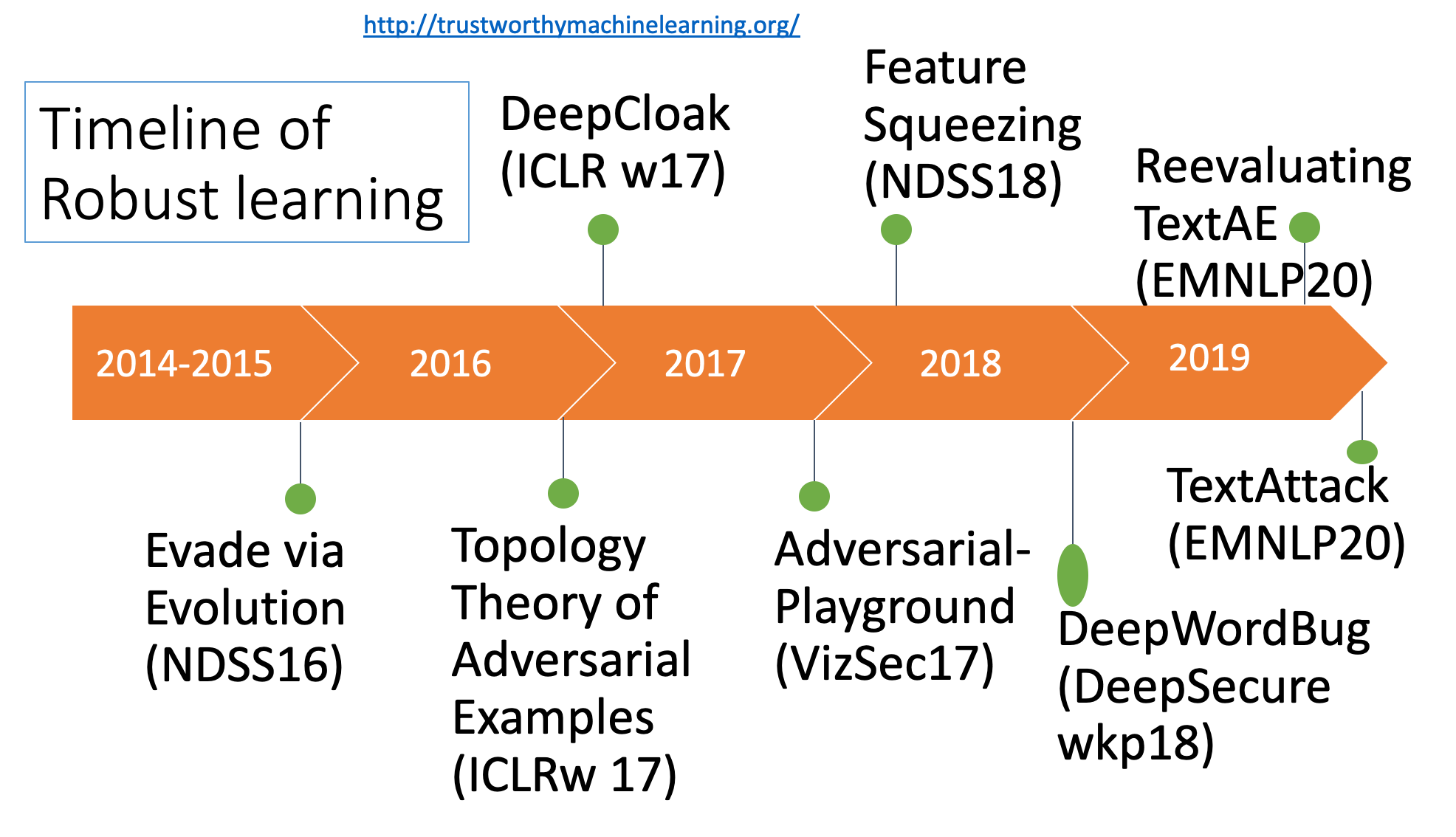
We categorize the topics into a list of subtasks and list our selected works in the following table:
Contact
Have questions or suggestions? Feel free to ask me on Twitter or email me.
Thanks for reading!