Systems and methods for semi-supervised relationship extraction
01 Mar 2010Title: Systems and methods for semi-supervised relationship extraction
- authors: Qi, Yanjun and Bai, Bing and Ning, Xia and Kuksa, Pavel
Paper1: Semi-supervised abstraction-augmented string kernel for multi-level bio-relation extraction
-
Talk: Slide
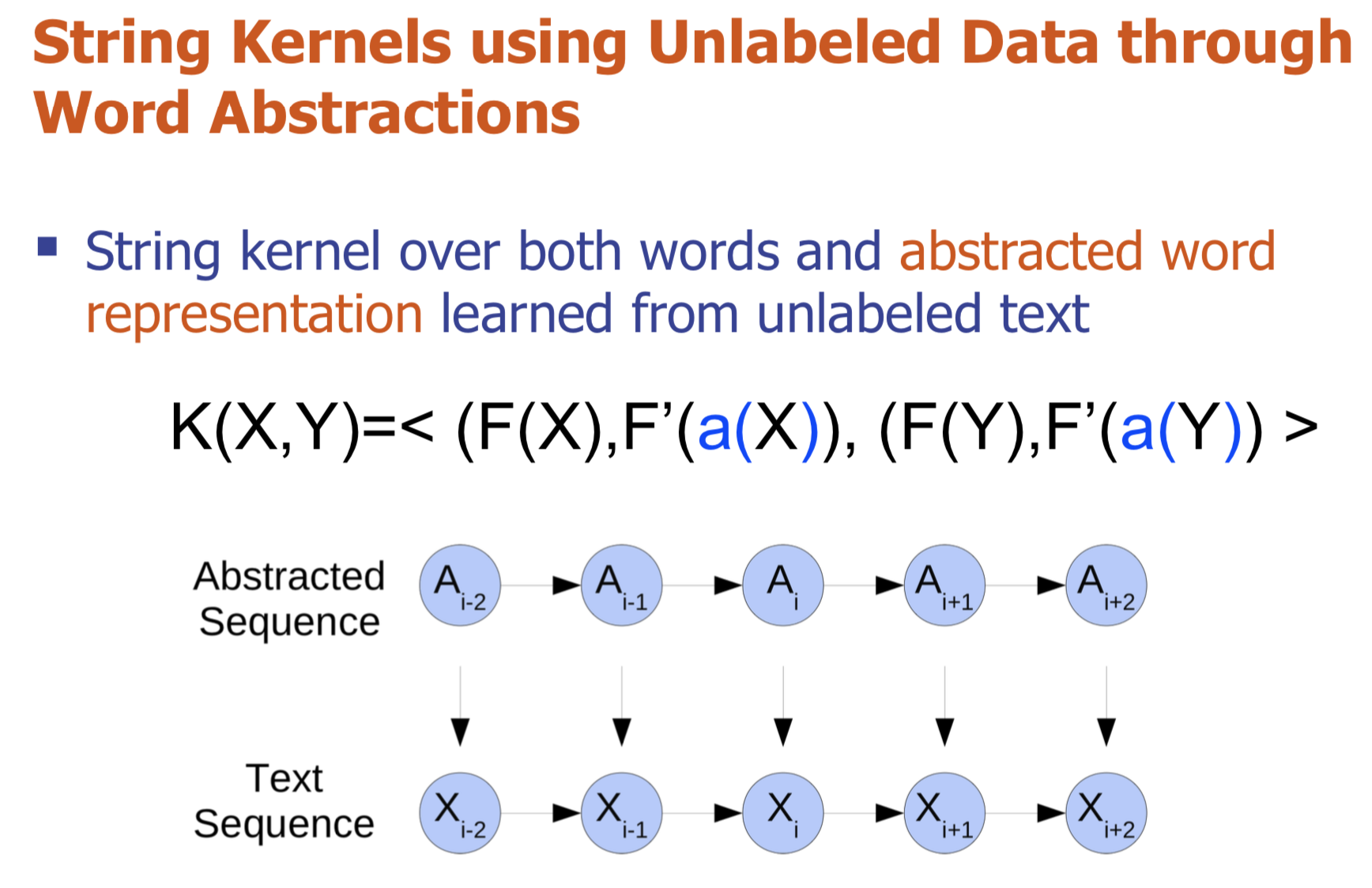
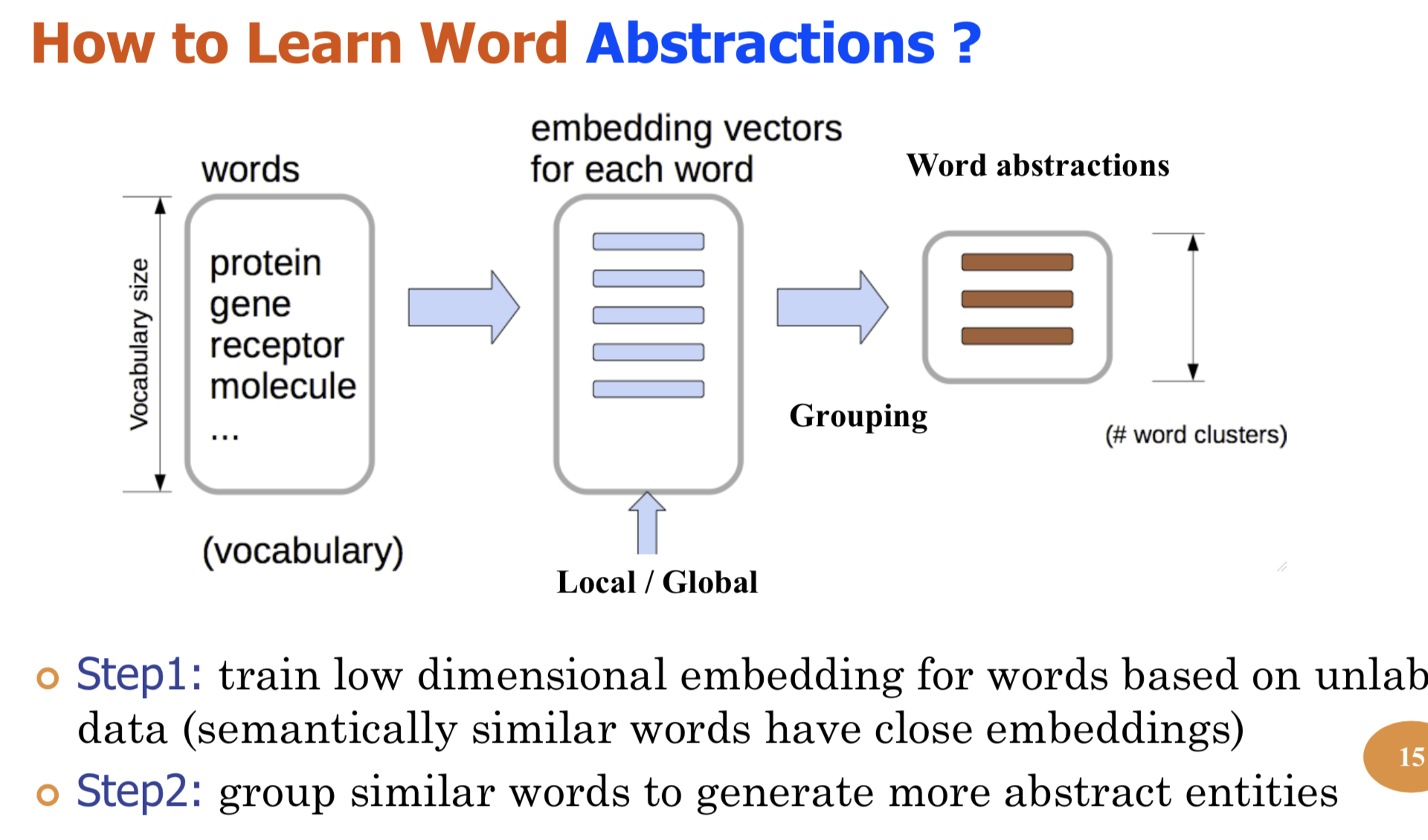
- Abstract Bio-relation extraction (bRE), an important goal in bio-text mining, involves subtasks identifying relationships between bio-entities in text at multiple levels, e.g., at the article, sentence or relation level. A key limitation of current bRE systems is that they are restricted by the availability of annotated corpora. In this work we introduce a semi-supervised approach that can tackle multi-level bRE via string comparisons with mismatches in the string kernel framework. Our string kernel implements an abstraction step, which groups similar words to generate more abstract entities, which can be learnt with unlabeled data. Specifically, two unsupervised models are proposed to capture contextual (local or global) semantic similarities between words from a large unannotated corpus. This Abstraction-augmented String Kernel (ASK) allows for better generalization of patterns learned from annotated data and provides a unified framework for solving bRE with multiple degrees of detail. ASK shows effective improvements over classic string kernels on four datasets and achieves state-of-the-art bRE performance without the need for complex linguistic features.
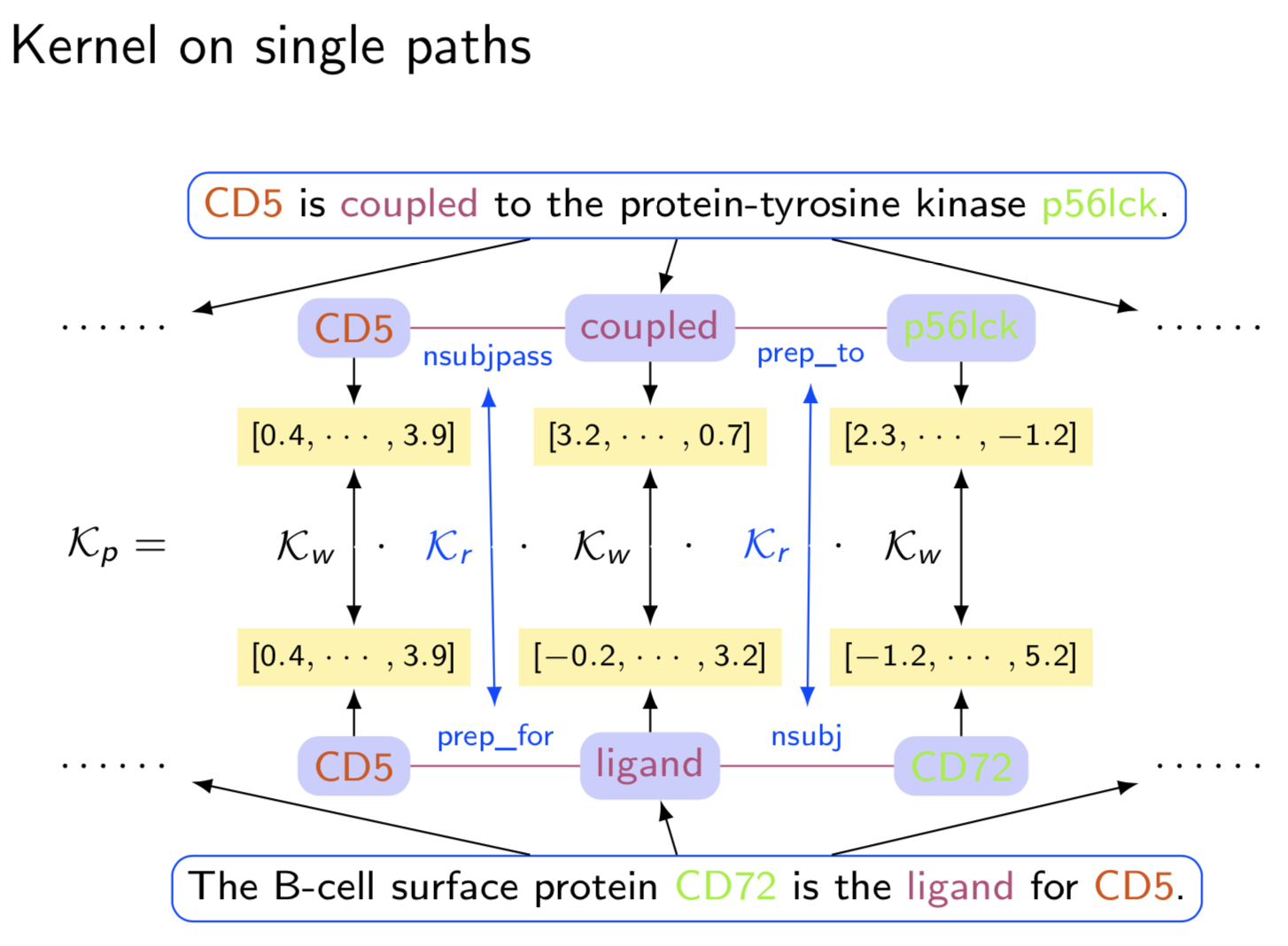
Paper2: Semi-Supervised Convolution Graph Kernels for Relation Extraction
- Talk: Slide
-
URL More
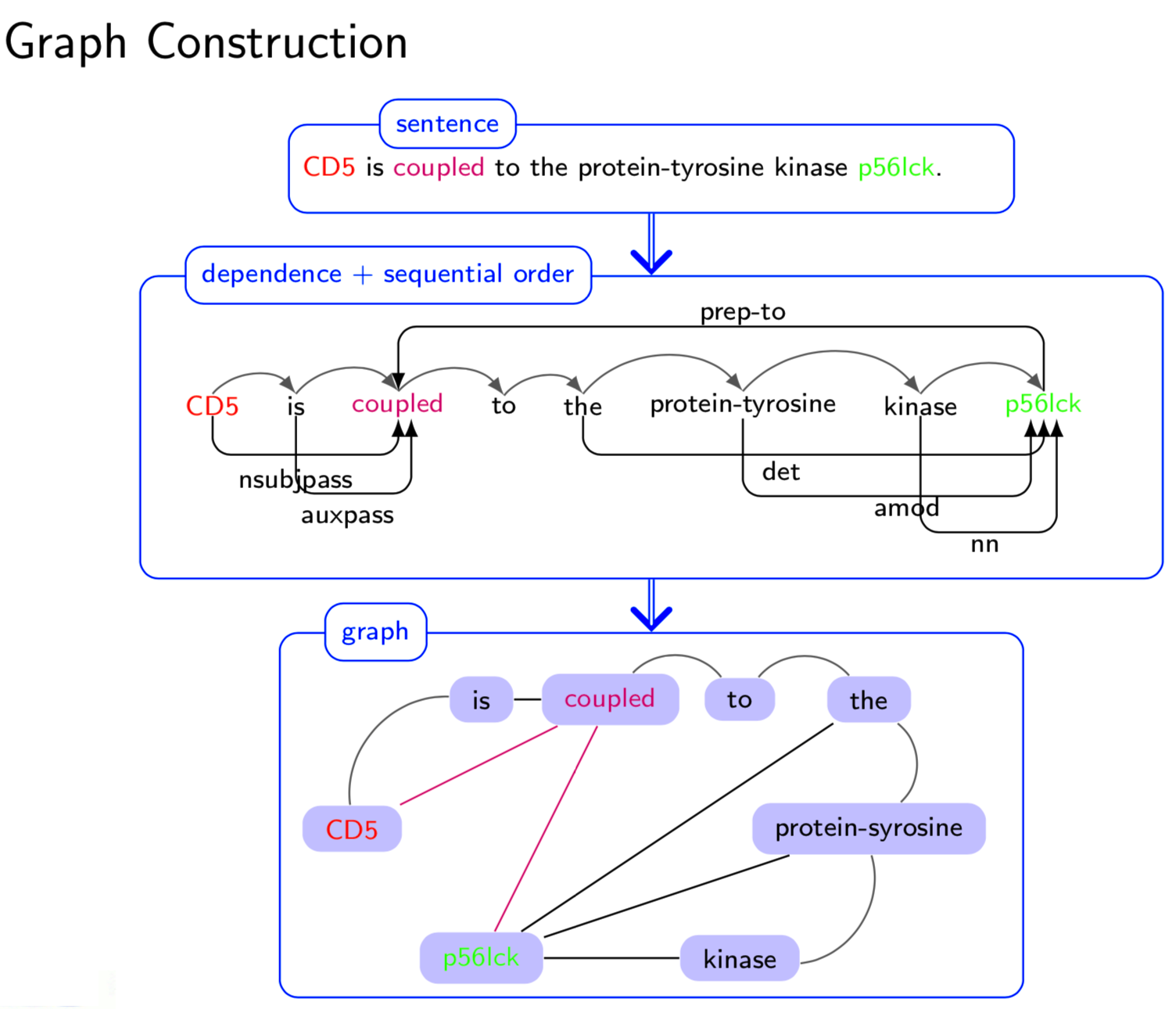
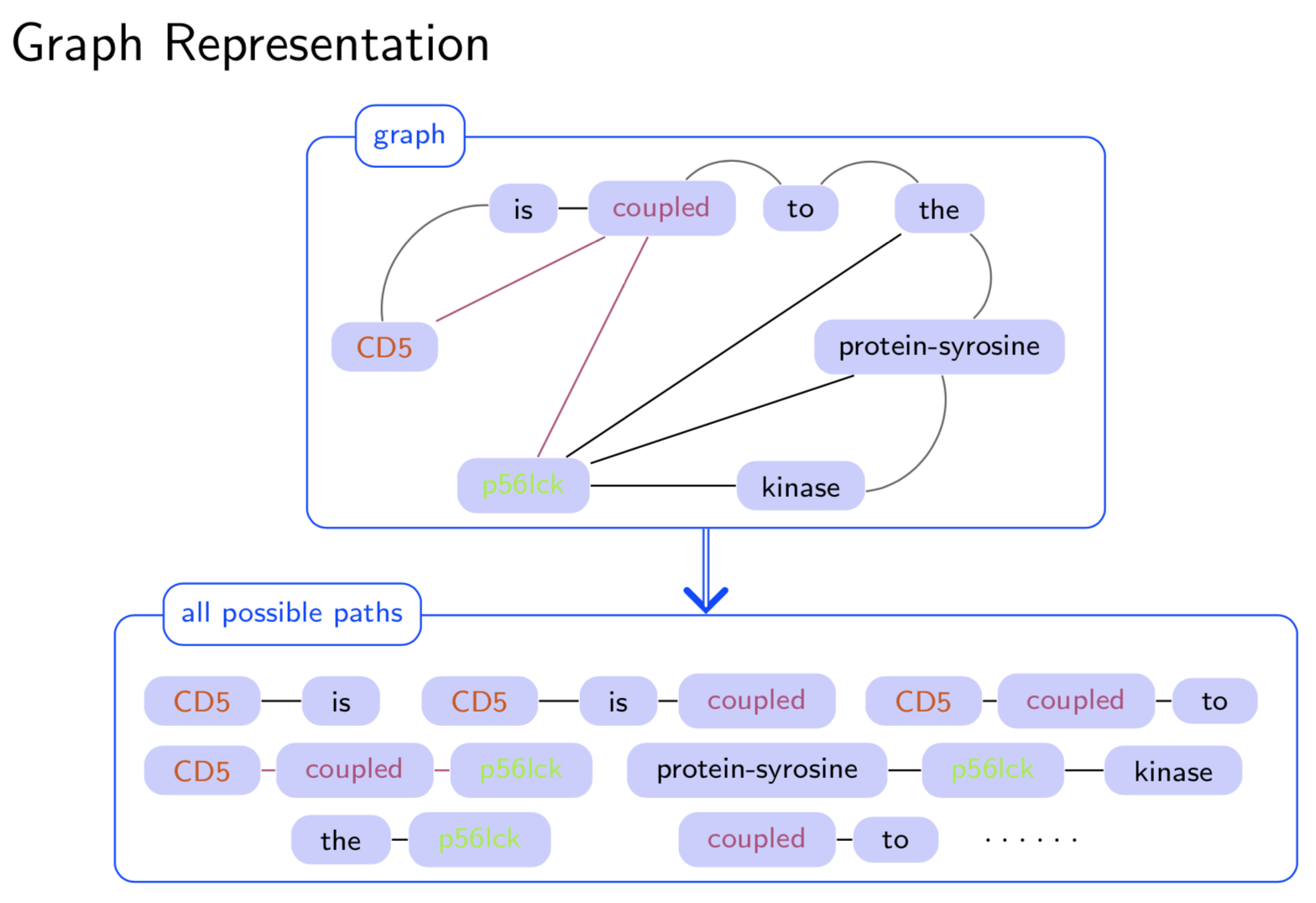
- Abstract Extracting semantic relations between entities is an important step towards automatic text understanding. In this paper, we propose a novel Semi-supervised Convolution Graph Kernel (SCGK) method for semantic Relation Extraction (RE) from natural language. By encoding English sentences as dependence graphs among words, SCGK computes kernels (similarities) between sentences using a convolution strategy, i.e., calculating similarities over all possible short single paths from two dependence graphs. Furthermore, SCGK adds three semi-supervised strategies in the kernel calculation to incorporate soft-matches between (1) words, (2) grammatical dependencies, and (3) entire sentences, respectively. From a large unannotated corpus, these semi-supervision steps learn to capture contextual semantic patterns of elements in natural sentences, which therefore alleviate the lack of annotated examples in most RE corpora. Through convolutions and multi-level semi-supervisions, SCGK provides a powerful model to encode both syntactic and semantic evidence existing in natural English sentences, which effectively recovers the target relational patterns of interest. We perform extensive experiments on five RE benchmark datasets which aim to identify interaction relations from biomedical literature. Our results demonstrate that SCGK achieves the state-of-the-art performance on the task of semantic relation extraction.
Paper3: Semi-Supervised Bio-Named Entity Recognition with Word-Codebook Learning
- Pavel P. Kuksa, Yanjun Qi,
- Abstract We describe a novel semi-supervised method called WordCodebook Learning (WCL), and apply it to the task of bionamed entity recognition (bioNER). Typical bioNER systems can be seen as tasks of assigning labels to words in bioliterature text. To improve supervised tagging, WCL learns a class of word-level feature embeddings to capture word semantic meanings or word label patterns from a large unlabeled corpus. Words are then clustered according to their embedding vectors through a vector quantization step, where each word is assigned into one of the codewords in a codebook. Finally codewords are treated as new word attributes and are added for entity labeling. Two types of wordcodebook learning are proposed: (1) General WCL, where an unsupervised method uses contextual semantic similarity of words to learn accurate word representations; (2) Task-oriented WCL, where for every word a semi-supervised method learns target-class label patterns from unlabeled data using supervised signals from trained bioNER model. Without the need for complex linguistic features, we demonstrate utility of WCL on the BioCreativeII gene name recognition competition data, where WCL yields state-of-the-art performance and shows great improvements over supervised baselines and semi-supervised counter peers.
Citations
@INPROCEEDINGS{ecml2010ask,
author = {Pavel P. Kuksa and Yanjun Qi and Bing Bai and Ronan Collobert and
Jason Weston and Vladimir Pavlovic and Xia Ning},
title = {Semi-Supervised Abstraction-Augmented String Kernel for Multi-Level
Bio-Relation Extraction},
booktitle = {ECML},
year = {2010},
note = {Acceptance rate: 106/658 (16%)},
bib2html_pubtype = {Refereed Conference},
}


Support or Contact
Having trouble with our tools? Please contact Yanjun Qi and we’ll help you sort it out.