We move the blogs on this research front to our Group-Blog-Site at https://qdata.github.io/qdata-page/ since 2021.
Background of Representation Learning and Deep Learning
The performance of machine learning algorithms is largely dependent on the data representation (or features) on which they are applied. Deep learning aims at discovering learning algorithms that can find multiple levels of representations directly from data, with higher levels representing more abstract concepts. In recent years, the field of deep learning has lead to groundbreaking performance in many applications such as computer vision, speech understanding, natural language processing, and computational biology.
Why Discrete Data is Interesting?
Deep learning constructs networks of parameterized functional modules and is trained from reference examples using gradient-based optimization [Lecun19].
Since it is hard to estimate gradients through functions of discrete random variables, researching on how to make deep learning behave well on discrete data and discrete representation interests us. Developing such techniques are an active research area. We focus on investigating interpretable and scalable techniques for doing so.
Relevant Papers we published
- Please check out each item in our side-bar
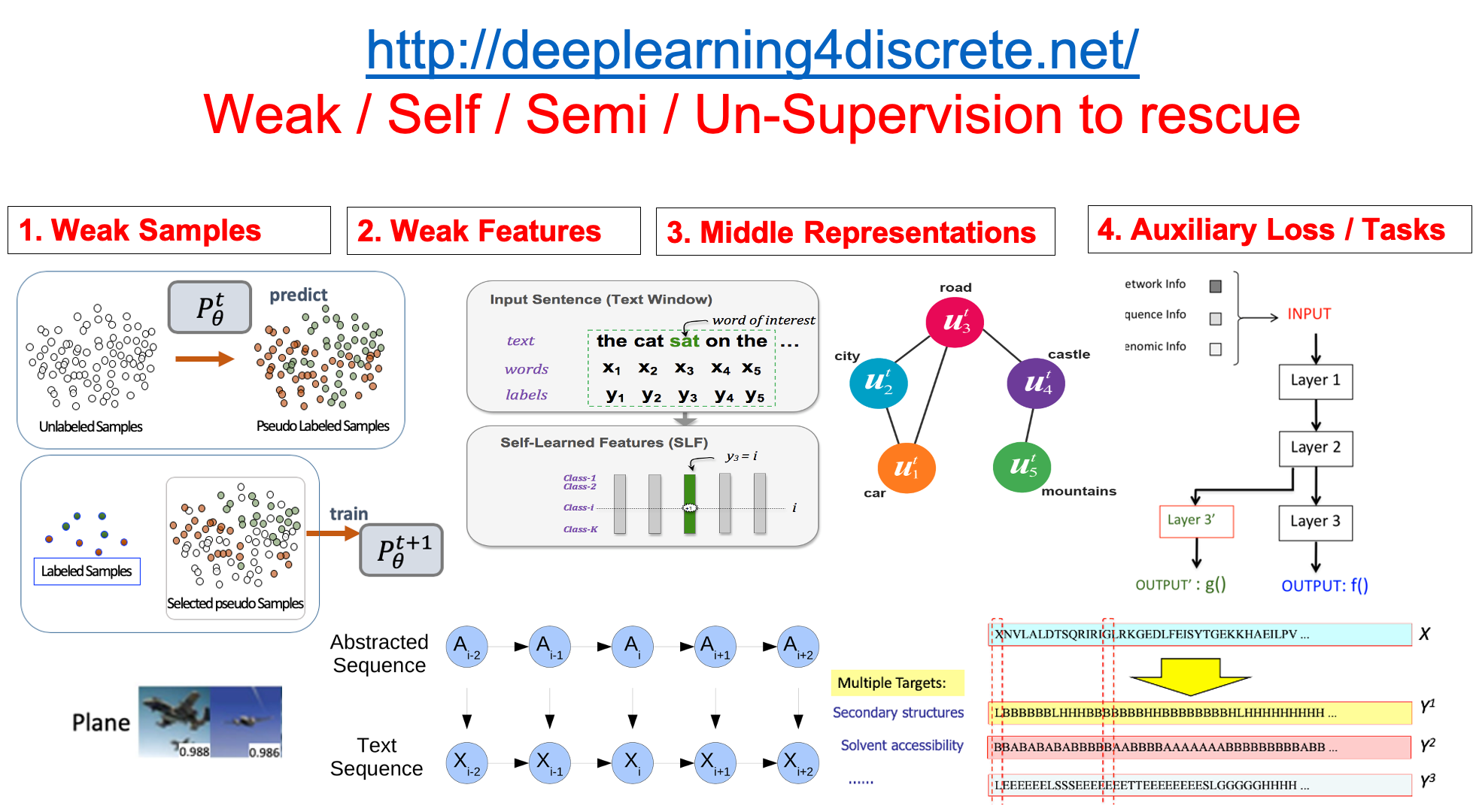
We have focused on weak supervision in multiple of our papers along this line of research.
Contacts:
Have questions or suggestions? Feel free to ask me on Twitter or email me.
Thanks for reading!