4-VisualizeBench
This category of tools aims to enable machine learning practitioners and users to understand how machine-learning models may be attacked..
This includes:
12 May 2020
Title: TextAttack: A Framework for Adversarial Attacks in Natural Language Processing
Abstract
TextAttack is a library for generating natural language adversarial examples to fool natural language processing (NLP) models. TextAttack builds attacks from four components: a search method, goal function, transformation, and a set of constraints. Researchers can use these components to easily assemble new attacks. Individual components can be isolated and compared for easier ablation studies. TextAttack currently supports attacks on models trained for text classification and entailment across a variety of datasets. Additionally, TextAttack’s modular design makes it easily extensible to new NLP tasks, models, and attack strategies. TextAttack code and tutorials are available at this https URL.
It is a Python framework for adversarial attacks, data augmentation, and model training in NLP.

Citations
@misc{morris2020textattack,
title={TextAttack: A Framework for Adversarial Attacks in Natural Language Processing},
author={John X. Morris and Eli Lifland and Jin Yong Yoo and Yanjun Qi},
year={2020},
eprint={2005.05909},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Having trouble with our tools? Please contact DrQ and we’ll help you sort it out.
12 Jan 2018
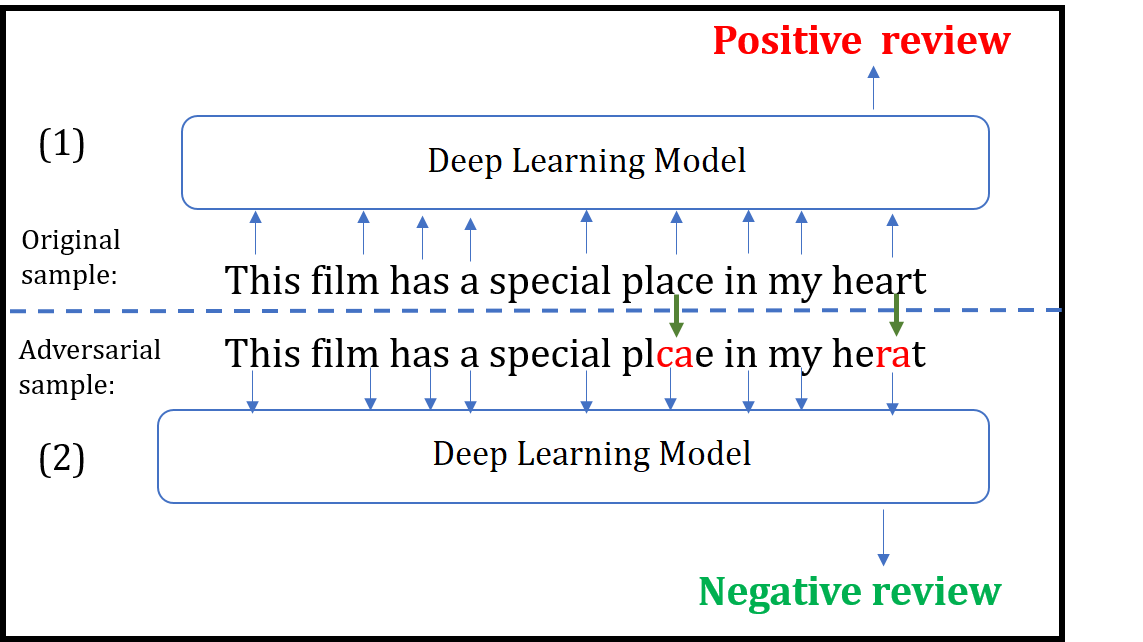
Title: Black-box Generation of Adversarial Text Sequences to Fool Deep Learning Classifiers
TalkSlide: URL
Published @ 2018 IEEE Security and Privacy Workshops (SPW),
co-located with the 39th IEEE Symposium on Security and Privacy.
Abstract
Although various techniques have been proposed to generate adversarial samples for white-box attacks on text, little attention has been paid to a black-box attack, which is a more realistic scenario. In this paper, we present a novel algorithm, DeepWordBug, to effectively generate small text perturbations in a black-box setting that forces a deep-learning classifier to misclassify a text input. We develop novel scoring strategies to find the most important words to modify such that the deep classifier makes a wrong prediction. Simple character-level transformations are applied to the highest-ranked words in order to minimize the edit distance of the perturbation. We evaluated DeepWordBug on two real-world text datasets: Enron spam emails and IMDB movie reviews. Our experimental results indicate that DeepWordBug can reduce the classification accuracy from 99% to around 40% on Enron data and from 87% to about 26% on IMDB. Also, our experimental results strongly demonstrate that the generated adversarial sequences from a deep-learning model can similarly evade other deep models.
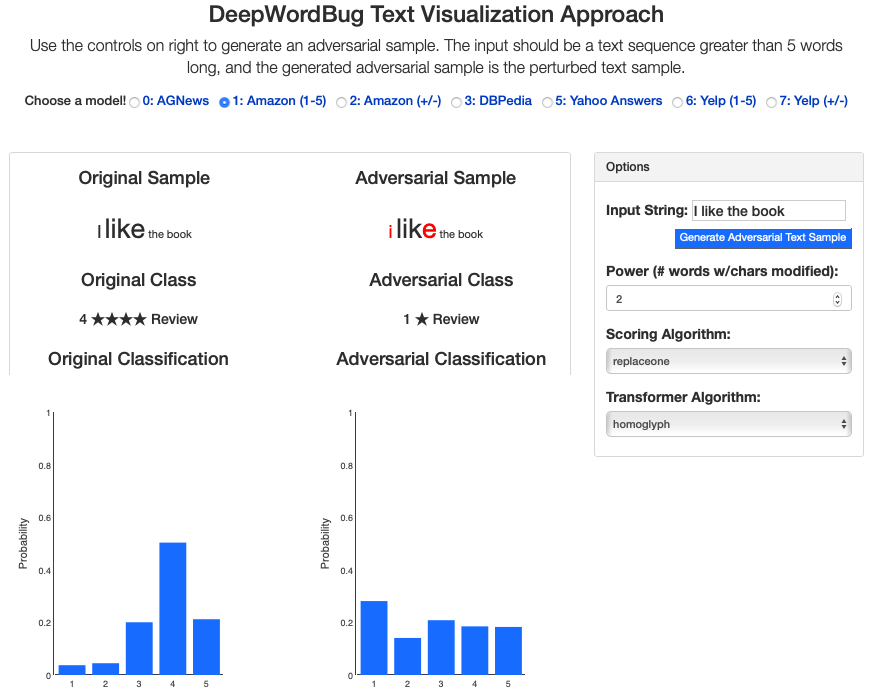
We build an interactive extension to visualize DeepWordbug:
- Interactive Live Demo @ ULR
Citations
@INPROCEEDINGS{JiDeepWordBug18,
author={J. Gao and J. Lanchantin and M. L. Soffa and Y. Qi},
booktitle={2018 IEEE Security and Privacy Workshops (SPW)},
title={Black-Box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers},
year={2018},
pages={50-56},
keywords={learning (artificial intelligence);pattern classification;program debugging;text analysis;deep learning classifiers;character-level transformations;IMDB movie reviews;Enron spam emails;real-world text datasets;scoring strategies;text input;text perturbations;DeepWordBug;black-box attack;adversarial text sequences;black-box generation;Perturbation methods;Machine learning;Task analysis;Recurrent neural networks;Prediction algorithms;Sentiment analysis;adversarial samples;black box attack;text classification;misclassification;word embedding;deep learning},
doi={10.1109/SPW.2018.00016},
month={May},}
Having trouble with our tools? Please contact me and we’ll help you sort it out.
12 Dec 2017
About
We have designed and implemented EvadeML-Zoo, a benchmarking and visualization tool for research on adversarial machine learning. The goal of EvadeML-Zoo is to ease the experimental setup and help researchers evaluate and verify their results.
EvadeML-Zoo has a modular architecture and is designed to make it easy to add new datasets, pre-trained target models, attack or defense algorithms. The code is open source under the MIT license.
We have integrated three popular datasets: MNIST, CIFAR-10 and ImageNet- ILSVRC with a simple and unified interface. We offer several representative pre-trained models with state-of-the-art accuracy for each dataset including two pre-trained models for ImageNet-ILSVRC: the heavy Inception-v3 and and the lightweight MobileNet. We use Keras to access the pre-trained models because it provides a simplified interface and it is compatible with TensorFlow, which is a flexible tool for implementing attack and defense techniques.
We have integrated several existing attack algorithms as baseline for the upcoming new methods, including FGSM, BIM, JSMA, Deepfool, Universal Adversarial Perturbations, and Carlini and Wagner’s algorithms.
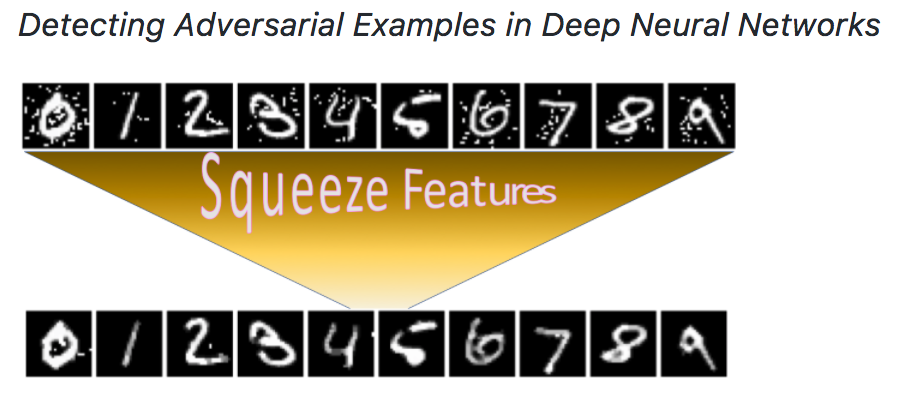
We have integrated our “feature squeezing” based detection framework in this toolbox. Formulating detecting adversarial examples as a binary classification task, we first construct a balanced dataset with equal number of legitimate and adversarial examples, and then split it into training and test subsets. A detection method has full access to the training set but no access to the labels of the test set. We measure the TPR and FPR on the test set as the benchmark detection results. Our Feature Squeezing functions as the detection baseline. Users can easily add more detection methods using our framework.
Besides, the tool comes with an interactive web-based visualization module adapted from our previous ADVERSARIAL-PLAYGROUND package. This module enables better understanding of the impact of attack algorithms on the resulting adversarial sample; users may specify attack algorithm parameters for a variety of attack types and generate new samples on-demand. The interface displays the resulting adversarial example as compared to the original, classification likelihoods, and the influence of a target model throughout layers of the network.
Citations
@inproceedings{Xu0Q18,
author = {Weilin Xu and
David Evans and
Yanjun Qi},
title = {Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks},
booktitle = {25th Annual Network and Distributed System Security Symposium, {NDSS}
2018, San Diego, California, USA, February 18-21, 2018},
year = {2018},
crossref = {DBLP:conf/ndss/2018},
url = {http://wp.internetsociety.org/ndss/wp-content/uploads/sites/25/2018/02/ndss2018\_03A-4\_Xu\_paper.pdf},
timestamp = {Thu, 09 Aug 2018 10:57:16 +0200},
biburl = {https://dblp.org/rec/bib/conf/ndss/Xu0Q18},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Having troubl with our tools? Please contact Weilin and we’ll help you sort it out.
03 Aug 2017
Revised Version2 Paper Arxiv
Revised Title: Adversarial-Playground: A Visualization Suite Showing How Adversarial Examples Fool Deep Learning
Publish @ The IEEE Symposium on Visualization for Cyber Security (VizSec) 2017 -ULR

Abstract
Recent studies have shown that attackers can force deep learning models to
misclassify so-called “adversarial examples”: maliciously generated images
formed by making imperceptible modifications to pixel values. With growing
interest in deep learning for security applications, it is important for
security experts and users of machine learning to recognize how learning
systems may be attacked. Due to the complex nature of deep learning, it is
challenging to understand how deep models can be fooled by adversarial
examples. Thus, we present a web-based visualization tool,
Adversarial-Playground, to demonstrate the efficacy of common adversarial
methods against a convolutional neural network (CNN) system.
Adversarial-Playground is educational, modular and interactive. (1) It enables
non-experts to compare examples visually and to understand why an adversarial
example can fool a CNN-based image classifier. (2) It can help security experts
explore more vulnerability of deep learning as a software module. (3) Building
an interactive visualization is challenging in this domain due to the large
feature space of image classification (generating adversarial examples is slow
in general and visualizing images are costly). Through multiple novel design
choices, our tool can provide fast and accurate responses to user requests.
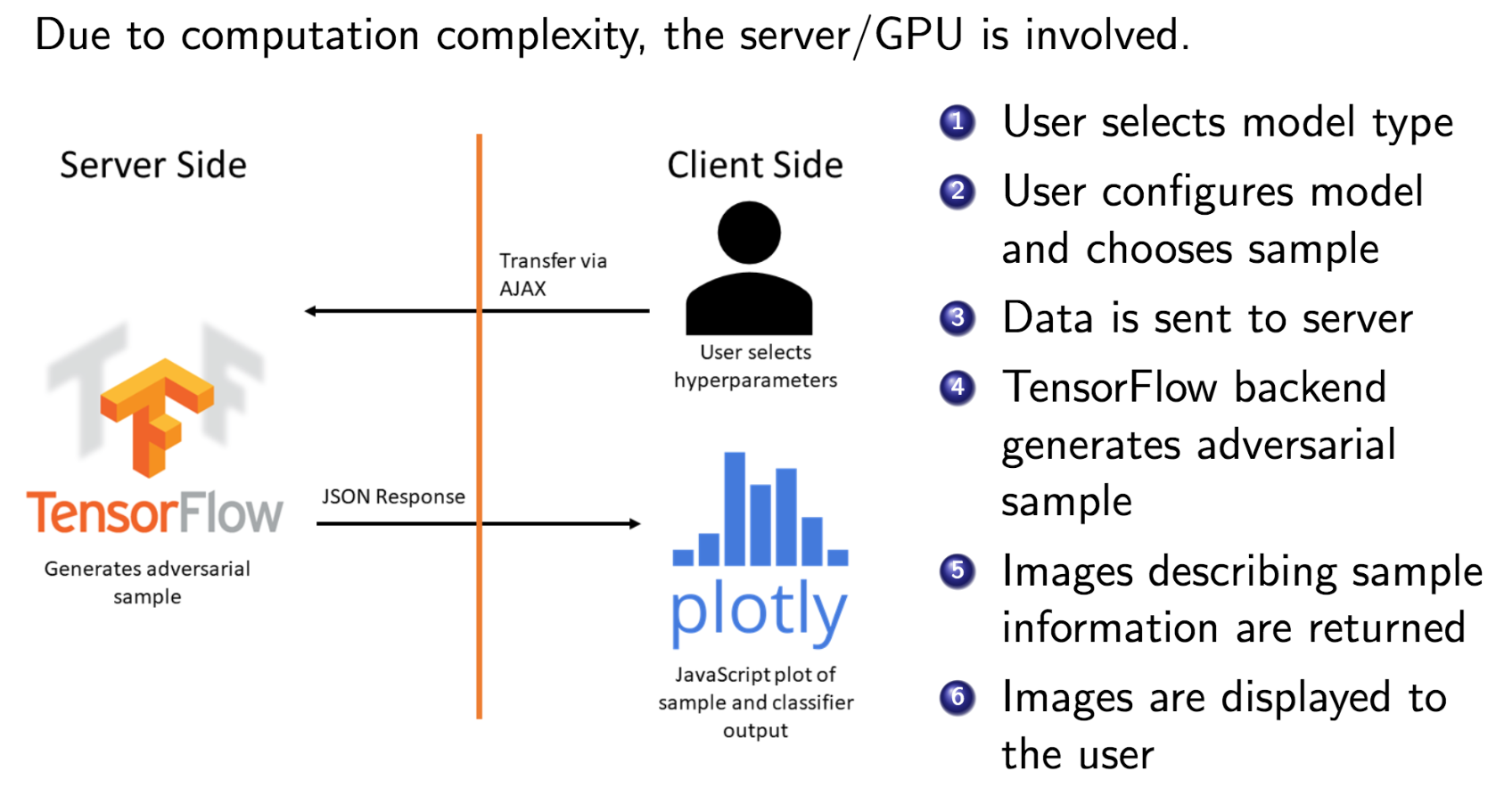
Empirically, we find that our client-server division strategy reduced the
response time by an average of 1.5 seconds per sample. Our other innovation, a
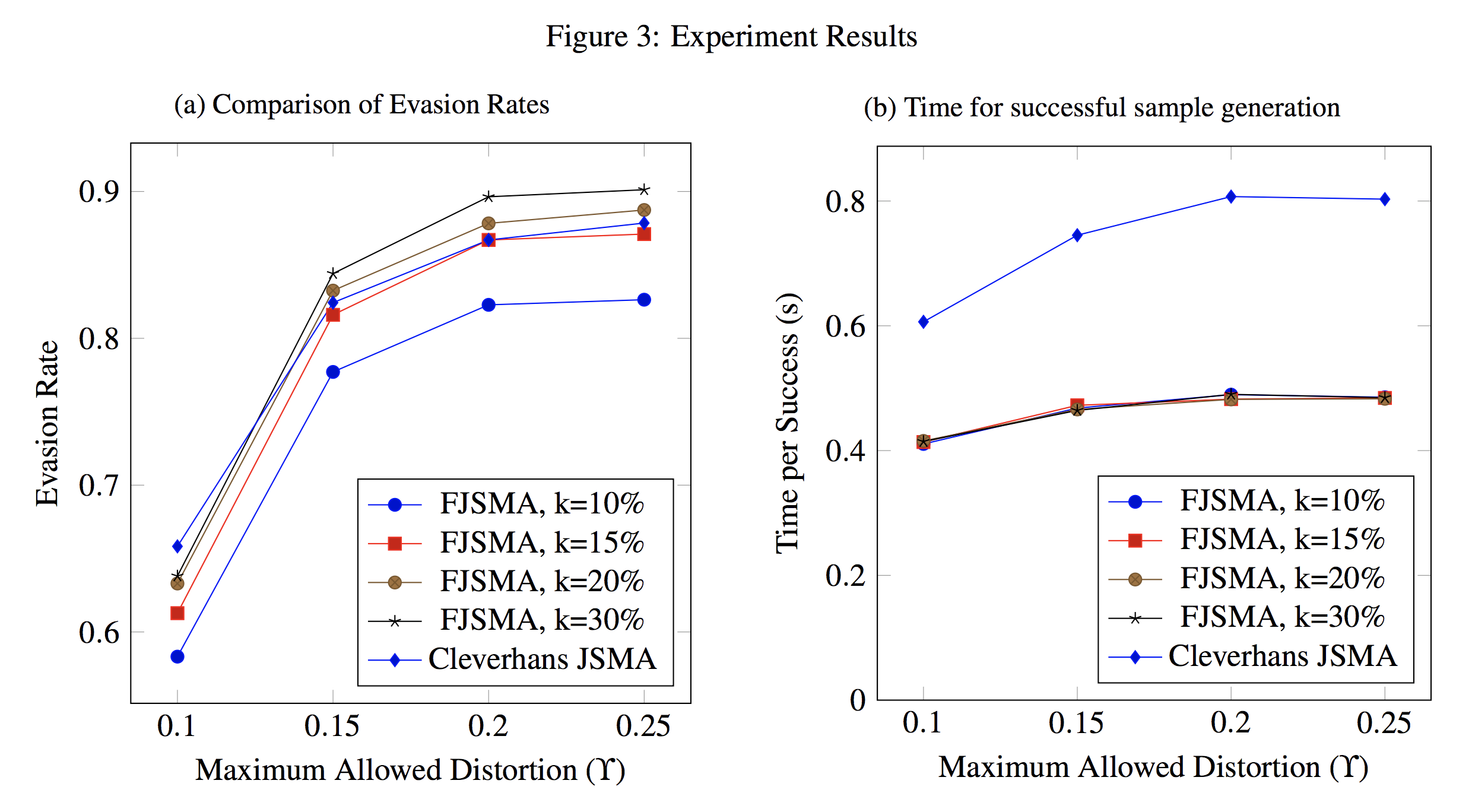
faster variant of JSMA evasion algorithm, empirically performed twice as fast
as JSMA and yet maintains a comparable evasion rate.
Project source code and data from our experiments available at:
GitHub
Citations
@inproceedings{norton2017adversarial,
title={Adversarial-Playground: A visualization suite showing how adversarial examples fool deep learning},
author={Norton, Andrew P and Qi, Yanjun},
booktitle={Visualization for Cyber Security (VizSec), 2017 IEEE Symposium on},
pages={1--4},
year={2017},
organization={IEEE}
}
Having trouble with our tools? Please contact Andrew Norton and we’ll help you sort it out.
04 Jun 2017
Abstract
With growing interest in adversarial machine learning, it is important for machine learning practitioners and users to understand how their models may be attacked. We propose a web-based visualization tool, \textit{Adversarial-Playground}, to demonstrate the efficacy of common adversarial methods against a deep neural network (DNN) model, built on top of the TensorFlow library. Adversarial-Playground provides users an efficient and effective experience in exploring techniques generating adversarial examples, which are inputs crafted by an adversary to fool a machine learning system. To enable Adversarial-Playground to generate quick and accurate responses for users, we use two primary tactics: (1) We propose a faster variant of the state-of-the-art Jacobian saliency map approach that maintains a comparable evasion rate. (2) Our visualization does not transmit the generated adversarial images to the client, but rather only the matrix describing the sample and the vector representing classification likelihoods.

Citations
@inproceedings{norton2017adversarial,
title={Adversarial-Playground: A visualization suite showing how adversarial examples fool deep learning},
author={Norton, Andrew P and Qi, Yanjun},
booktitle={Visualization for Cyber Security (VizSec), 2017 IEEE Symposium on},
pages={1--4},
year={2017},
organization={IEEE}
}
Having trouble with our tools? Please contact Andrew Norton and we’ll help you sort it out.